Comment fonctionnent les simulateurs LexImpact ?
1. Ce que les simulateurs permettent d'estimer
LexImpact propose un simulateur socio-fiscal permettant d'estimer les impacts d'une réforme paramétrique sur les impôts, les cotisations et les prestations sociales à destination des ménages. Cet outil permet aux utilisateurs :
- d'estimer, en moins d'une minute, l'impact financier sur des ménages types configurables ;
- d'obtenir l'impact sur les recettes de l'État et de la Sécurité sociale et plus généralement sur la population française, d'une évolution de l'impôt sur le revenu et de la CSG prélevée sur les salaires et les retraites.
LexImpact a également conçu un simulateur concernant les dotations de l'État aux communes. Ce simulateur, toujours accessible, n'est plus à jour depuis fin 2021.
Le simulateur de l'impôt sur le revenu permet d'estimer les impacts sur :
- des foyers fiscaux configurables ;
- les recettes totales et par dixièmes, ainsi que le nombre de ménages
concernés de :
- de l'impôt sur le revenu ;
- de la CSG prélevée sur les salaires ;
- de la CSG prélevée sur les retraites.

Le simulateur des dotations aux communes permet d'estimer les impacts sur :
- chaque commune de France ;
- chaque strate démographique de communes.
Des impacts sur cas-types
Les simulateurs LexImpact permettent de configurer des cas-types pour ensuite visualiser les impacts de la loi ou d'une réforme paramétrique sur ces derniers. Un cas-type est un cas simplifié d'une situation individuelle, par exemple : "un foyer composé de deux adultes et d'un enfant, gagnant un certain salaire par mois". En configurant plusieurs cas-types sur les simulateurs LexImpact, l'utilisateur peut alors se représenter, de façon simplifiée, les impacts sur différents types de population.
Des situations simplifiées à mettre en perspective
Les estimations sur cas-types sont plus précises que les estimations d'impacts globaux sur la population française, qui eux, dépendent des données disponibles. En revanche, du fait de leur caractère simplifié, elles sont à mettre en perspective avec la réalité du terrain :
- Premièrement en regard de leur proportion dans la population réelle difficile à évaluer : Par exemple, l'utilisateur crée deux cas types très simplifiés, l'un représentant un salarié du privé gagnant le SMIC, l'autre représentant un salarié du privé gagnant 6000 euros par mois. Les deux cas types sont affichés à l'écran, pourtant l'un regroupe une situation simplifiée représentative de beaucoup de salariés, l'autre concerne une situation bien moins étendue. Plus l'utilisateur configure son cas type en détail, moins il est évident de savoir combien de personnes réelles peuvent être associées à ce cas type.
- Deuxièmement, il n'est pas possible de tirer d'une estimation concernant un cas-type, des conclusions sur une situation individuelle précise. Il faudrait pour cela entrer l'ensemble des paramètres ayant une influence sur le dispositif à évaluer concernant une personne réelle, à l'instar des déclarations de revenus, et les simulateurs LexImpact n'ont pas cette vocation.
Dans le cadre des dotations aux communes, le simulateur ne permet pas de créer un cas-type de commune puisque l'ensemble des communes sont accessibles par le biais de la barre de recherche. La possibilité de rechercher les communes et de les afficher permet d'effectuer des comparaisons.
Des impacts globaux
En plus des impacts sur cas-types, LexImpact permet d'estimer les effets globaux (sans être comportementaux) d'une modification de la loi. Pour cela, les simulateurs s'appuient sur des données représentatives ou exhaustives de la population française :

Simulateur des cotisations & prestations sociale :
Simulateur des dotations aux communes :
- Critères de répartition des dotations par commune de la Direction Générale des collectivités locales (DGCL) (millésime 2016)- Données ouvertes 🔓.
2. Fonctionnement des simulateurs
Un fonctionnement possible grâce à plusieurs acteurs
LexImpact bénéficie d'un écosystème composé de plusieurs acteurs :
- En amont, les fournisseurs de données. Qu'il s'agisse de données publiques, ou de données protégées, cet écosystème est indispensable pour permettre d'estimer les impacts d'une réforme sur la population française et sur le budget de l'État ou de la Sécurité sociale.
- Autant pour le traitement des données que pour le moteur de calcul,
LexImpact échange régulièrement avec des experts techniques et métiers
dont le domaine de compétences est reconnu. L'ensemble de ces contributions
est visible dans
notre code source.
Les administrateurs de l'Assemblée nationale, experts des questions juridiques, financières et économiques nous apportent leur expertise métier à la fois pour le moteur de calcul et l'interface. Pour le simulateur socio-fiscal, ils participent à la vérification des paramètres et des formules directement depuis l'interface. - Enfin, les services LexImpact reposent sur l'analyse des besoins utilisateurs et sur la prise en compte des retours utilisateurs, dans une logique d'amélioration continue. Les statistiques d'usage des produits sont disponibles ici.
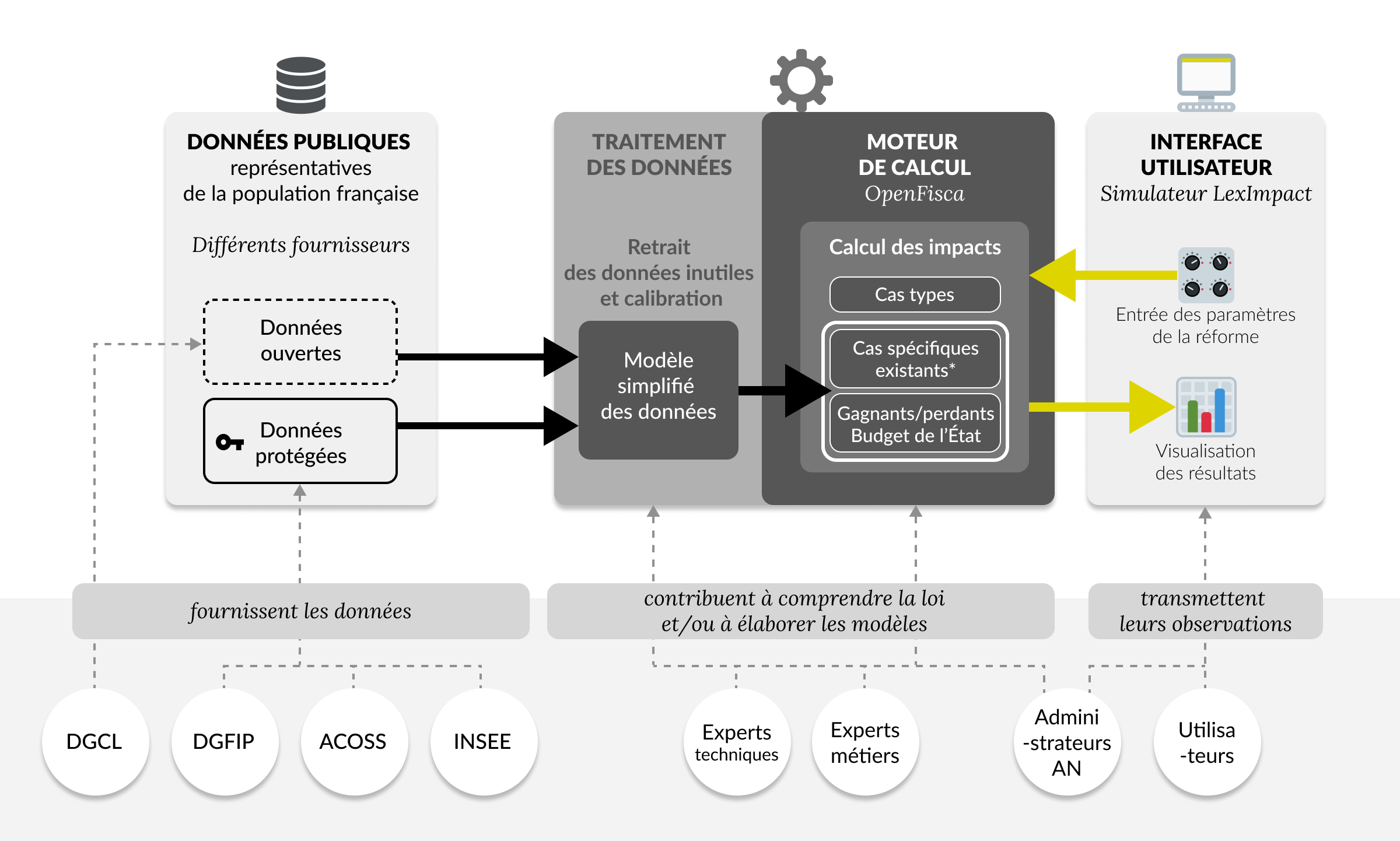
* Le calcul d'impact sur des cas spécifiques est possible uniquement pour des entités dont les données sont entièrements publiques. Actuellement, seul le simulateur “Dotations aux communes” est concerné par les cas spécifiques des communes de France. Cela n'est pas possible pour les entreprises et les foyers fiscaux, dont les données sont protégées.
Le traitement des données
Les données exhaustives sur la population qui sont utilisées pour les calibrer les calculs sur le budget de l'État sont protégées par le secret statistique, et ne peuvent pas être sorties du Centre d'accès sécurisés au données (CASD). Or, afin de permettre à nos utilisateurs de faire eux-mêmes des simulations, il faut que ces données soient accessibles depuis le simulateur en ligne pour effectuer les calculs : il faut donc des données accessibles. De plus, pour offrir une réponse quasi-immédiate, il est nécessaire de limiter les données manipulées pour réduire le temps de calcul. Les données dont l'impact sur le résultat final est négligeable sont par exemple supprimées.
C'est pourquoi LexImpact utilise un modèle simplifié, c'est-à-dire un
échantillonnage des données qui représente le plus fidèlement toute la
population, et ce, pour tous les dispositifs socio-fiscaux qu'il est
possible de modifier. Il s'agit de la base de données ERFS-FPR,
échantillonnée spécifiquement par l'INSEE afin de permettre par la suite
de recalculer précisément des informations sur l'ensemble de la
population. Cependant elle ne contient pas toutes les données dont nous
avons besoin.
C'est pourquoi, afin d'obtenir notre modèle
final, plusieurs étapes sont nécessaires :
- Sélection : nous sélectionnons dans la base exhaustive POTE les données minimales nécessaires pour faire nos différents calculs. Par exemple, pour la CSG sur les revenus du capital, nous avons besoin, pour chaque foyer fiscal, des valeurs entrant dans le calcul de l'assiette de CSG du capital, comme les revenus fonciers. Cependant une simplification doit être faite pour limiter le temps de calcul, en omettant par exemple les produits sur gains financiers taxables à 50%, qui représentent moins de 0.0002% de l'assiette de la CSG sur les revenus du capital.
- Extraction : les données sélectionnées sont ensuite extraites du CASD en les agrégeant (par exemple en centiles) afin de respecter le Secret Statistique. La finesse de la distribution est ensuite un compromis entre la précision sur la population et le temps de calcul.
- Intégration : ces données sont ensuite réparties dans la base de données ERFS-FPR de l'INSEE pour l'améliorer.
- Mise à jour : la base ERFS-FPR étant plus ancienne que la base POTE, elle est mise à jour, avec notamment l'augmentation du nombre de foyers fiscaux et l'inflation de certaines variables.
- Anonymisation : afin de garantir un niveau supplémentaire de sécurité, un léger bruitage gaussien est appliqué sur toute la base.
- Calibration : enfin, au vu de l'ensemble des hypothèses de calcul faites lors de la génération de notre base, nous vérifions sa pertinence en effectuant plusieurs calculs et en comparant nos résultats aux chiffres officiels. La base est ainsi re-calibrée jusqu'à l'obtention de résultats pertinents pour tous les types de calculs.
Retrouvez en détail les étapes du traitement des données dans la documentation technique :
Le moteur de calcul
LexImpact utilise le calculateur OpenFisca. Cet outil est un calculateur qui applique la loi: si on lui entre une situation donnée, il peut calculer l'impôt d'une personne, ou les taxes d'une entreprise.
Logiciel open-source et collaboratif, OpenFisca a été créé en 2011 au sein de France Stratégie en partenariat avec l'Institut d'économie publique (IDEP) afin de permettre une plus grande transparence de la législation fiscale et sociale et une meilleure appréhension de celle-ci par les citoyens. Aujourd'hui, il est utilisé par différents organismes, tels que l'ANCT (Agence nationale de la cohésion des territoires), la Direction de la sécurité sociale, l'IPP (Institut des politiques publiques), Beta.gouv (service rattaché à la Direction interministerielle du Numérique), et est développé, mis à jour et vérifié par des contributeurs du monde entier.
3. Fiabilité des résultats
Méthodologie de vérification des résultats
Plusieurs mécanismes sont en place pour s'assurer de la qualité des résultats :
- Mise au point des algorithmes sur des petits jeux de données : Pour mettre au point les algorithmes nous générons manuellement des jeux de données de test idéaux pour confirmer que l'algorithme produit bien le résultat attendu par la théorie.
- Tests avec des données que l'on connait déjà : Ensuite nous demandons à l'algorithme de produire des données que nous connaissons déjà. Nous pouvons ainsi mesurer l'écart entre les résultats obtenus et la réalité.
- Contrôles des résultats vis à vis d'agregats : Pour les données dont nous n'avons pas de détails disponibles nous avons parfois accès à la somme total. Par exemple, en août 2021, la dernière enquête ERFS-FPR de l'INSEE disponible concerne 2018, mais l'INSEE publie le montant global des recettes de l'impôt en 2020. Nous pouvons utiliser ce chiffre pour vérifier si la somme de nos simulations pour 2020 s'en rapproche. Et même l'utiliser pour corriger nos données.
- Contrôle des résultats de simulations unitaires : Pour vérifier que les simulations sont correctes nous réalisons également des tests manuels sur des cas particuliers. On peut ainsi confronter nos résultats à d'autres simulateurs. Ou encore à des simulations réalisées avec le même simulateur sur les jeux de données complets auxquels nous avons accès mais que nous ne pouvons pas utiliser dans le simulateur en ligne.
- Tests automatiques : Nous utilisons un systéme dit d'intégration continue. C'est à dire qu'après chaque modifications de l'application des tests automatisées sont automatiquement exécutés sur l'ensemble de l'application. Cela permet de s'assurer que nous n'introduisons pas de bugs lors des évolutions. Cela limite les tests manuels à réaliser et nous permet de livrer plus rapidement des nouveautés.
Une marge d'erreur incompressible
Les résultats des simulateurs LexImpact ont, comme c'est le cas de tout simulateur, une certaine imprécision. Ils fournissent des estimations. Le calcul d'une marge d'erreur est impossible car l'imprécision provient de l'intrication de différents écarts ayant plusieurs origines :
- La mise à jour du moteur de calcul : Les simulateurs LexImpact s'appuient sur un calculateur. Celui-ci est codé en langage Python, et ses formules reflètent la loi existante. La législation, en matière fiscale et de sécurité sociale, évoluant au moins tous les ans, il est nécessaire de mettre à jour ce moteur de calcul, en recodant des formules et des paramètres. Cette mise à jour ne débute qu'après publication de la loi au Journal officiel, et nécessite un temps plus ou moins long. LexImpact s'appuie sur le moteur de calcul OpenFisca et, malgré les nombreuses contributions, la mise à jour est progressive étant donné le large périmètre du modèle. Le service LexImpact commence par les dispositifs qui pèsent le plus lourd dans les calculs, jusqu'à obtenir des résultats cohérents, mais un petit écart non significatif peut subsister.
- La simplification d'une situation : Que ce soit pour le calcul des cas-types ou pour le calcul d'impacts sur la population française, les paramètres définissant l'entité pour laquelle l'impact est calculé sont toujours simplifiés. Dans le cas d'impacts globaux, les données sont parfois simplement inexistantes ; pour les cas types, l'entrée de l'ensemble des paramètres serait extrêmement fastidieuse pour l'utilisateur et représenterait un coût de de développement logiciel très élevé. Par conséquent, pour limiter les développements, le temps de calcul et faciliter le parcours utilisateur, LexImpact prend des valeurs moyennes ou par défaut (souvent zéro) pour toutes les données qui ont un faible poids dans le résultat final. Par exemple, dans le cas du calcul de la CSG d'un ménage au SMIC avec deux enfants, les paramètres tels que les heures supplémentaires, les intérêts perçus sur un PEL de moins de 12 ans, ou encore les titres non côtés détenus dans le PEA, sont mis à 0. L'utilisation de valeurs par défaut ou moyennes génère donc un écart par rapport aux situations réelles individuelles.
- Les données représentatives de la population française : Souvent décalées dans le temps car mises à disposition avec un délai de 1 à 2 ans, les bases de données présentent parfois des erreurs d'entrée, des doublons, des manques, ou tout simplement des biais dans le cas où la base de données est construite à partir d'un échantillon de la population. On parle alors d'erreur de "sample". Comment expliqué dans la partie précédente (traitement des données), le service LexImpact traite ces informations pour réduire les écarts, mais ce traitement ne permet pas d'obtenir un résultat 100% conforme à la réalité.
Pour réduire les marges d'erreur, l'équipe LexImpact travaille en continu à l'amélioration du modèle, échange régulièrement avec des experts. Compte tenu de ce travail de validation, les résulats présentés sont cohérents et permettent de mettre en évidence les effets de différents dispositifs sur des ménages et sur l'État, avec une marge d'erreur raisonnable, mais qu'il faut garder à l'esprit.
Aidez à améliorer LexImpact, n'hésitez pas à contribuer !